Kubernetes: My Cluster Today
Nota Bene: This was written well before it got posted, cluster has been re-built, new post to come.
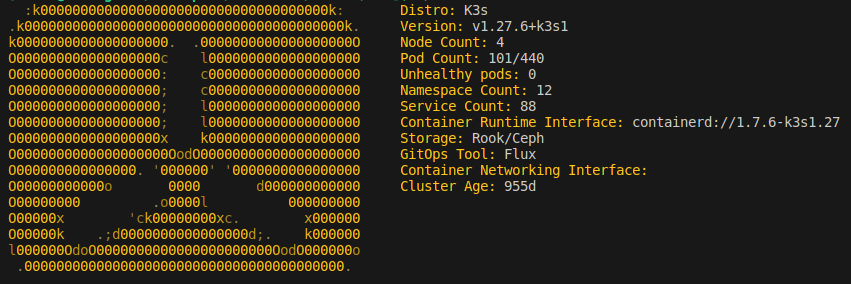
I am on the verge of retiring some of my current infrastructure that has been serving me well for about four years. My current Kubernetes cluster has been operational on this hardware coming up on three years. It is surprising I have lasted this long before the itch to change something caused me to buy something new… But, before I go into anything about the hardware I have purchased and plans that I have for it, I figured I might as well document the state of my compute world today (at least as far as it pertains to my home Kubernetes cluster).
My current infrastructure started to take shape in late 2019 when I had acquired a 24U APC rack from a local tech recycler in Atlanta and wanted to get some real “Enterprise” hardware to fill it. The backbone hardware for the rack became an HP DL380P Gen 8 server, formerly used by Travelocity (if the ILO configuration on the server is to be believed). It sported two Intel Xeon E5-2640 CPUs running at 2.5 GHz with 6 cores and 12 threads each, 96GB of DDR3 ECC memory, and 8 x 300 GB 10K SAS drives in a RAID 10 configuration. All-in-all, this is still a beefy server, even 10+ years on from when it was released, but it is showing a bit of its age.
For the first year of the server’s life it ran bespoke virtual machines for each of the services that I wanted to run. This works just fine and probably would have worked well enough for most things I wanted to do, but I had an itch to try something new and instead planned out a Kubernetes installation. The installation would consist of a single control-plane/master node and three compute/worker nodes all running on the aforementioned server. Not an ideal situation, given all the compute is localized to a single physical server, but it would allow me to learn, grow, rebuild, test, destroy, and build again without the pain of physical interaction with multiple servers. The compute VMs are currently configured with 6 vCPU, 24GB of ram, a 164 GB boot volume, and a 128GB data volume for Ceph.
Post-pandemic changing the world, I had the idea to explore expanding the cluster with a multi-architecture setup. This was partially to explore other low-power solutions to running local services, and partially because that itch hit again. I ended up adding three more compute nodes in the form of the Raspberry Pi 4 - 8GB model with PoE hats and mounted in the top of my rack. They are not super powerful, but with the targeted use of tolerations I am able to deploy only reasonable loads tot he nodes. All in all, they are working well for what I am asking of them.
To support the quick iterations I was going through I used Flux CD, a GitOps tool that allows me to declaratively define the state of my cluster as code. A huge credit to those over at the Home Operations discord community for all the assistance I received early in my kubernetes experience. I went through a few iterations of core deployments that support the cluster (such as trying out Longhorn and eventually moving to Rook-Ceph, or starting out with Authentik and moving to an OpenLDAP+Authelia system) to get the system that you can explore today on my gitops repository.
Hope to have another post out there soon-ish once I have my plan in place (and most likely executed).